先做个广告:需要购买Gemini帐号或代充值Gemini会员,请加微信:gptchongzhi
这次Google发布的内容非常的多,先把主要的内容做个总结。
 推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
1 发布了Gemini,这是一个原生的(Native)的多模态大模型,同时支持text文本,image图像,video视频和audio音频输入,支持文本和图片的输出。
2 Gemini有三个版本,Ultra,Pro和Nano,性能依次递减,Ultra略强于GPT4v,Pro跟3.5相当,Nano是手持设备上可用的,有1.8B和3.25B两个版本
3 Gemini Ultra性能在多模态的测试上表现比GPT4v要强,极少部分弱于GPT4v。
4 AlphaCode2发布,由Gemini加成,可能是人和AI协同编程的开端。
5 复杂推理能力Sophisticated reasoning,其中一个表现是可以很短的时间内通读20万篇论文并总结,非常适合科学家的一个特性
6 Anything to Anything: 可以将包括担不限于视频,音频,图像输入到程序代码,图片和文字等等。
7 直接处理音频文件,不需要将音频转为文字,保留更多的数据,比如发音,甚至中文音调,也可以做voice-image-text等多模态的组合应用。
8 Google Bard从今天起会融合Gemini Pro,差不多就是ChatGPT3.5的性能
9 Google的 Pixel 8手机会融合Gemini Nano移动端大模型,可以做一些总结录音等应用,会在WhatsApp等应用中率先使用。
10 Gemini Ultra,也就是最强的版本,现在正在做安全检测保证其安全,大约会在明年早些时间开放;届时Google Bard会融合进去,变成Bard Advanced。
内容真的非常的多,不过总结一下就是Gemini这个大模型的发布,其余的都是围绕它做的各种创新性的应用,它最强的点应该就是很多测试超过GPT4v,但是没有发布给大众,暂时只能用融合了Gemini Pro的Bard进行体验。
Gemini
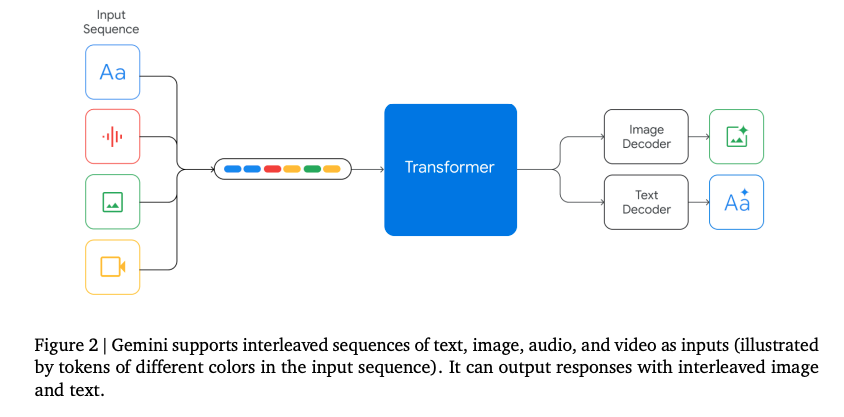
这是Google发布的新的大模型,它最大的特性就是原生多模态(native multimodality),这也是Google多次强调的特性,可以无缝的理解和操作包括文本、代码、音频、图像和视频在内的不同类型的信息。
Google 用这张图来表现原生多模态的特性,这个任务大意就是让Gemini先去理解这个图,然后根据指示来写代码重新绘制这些图,同时还要改变这些图的位置,这里面包含了四个多模态特性。
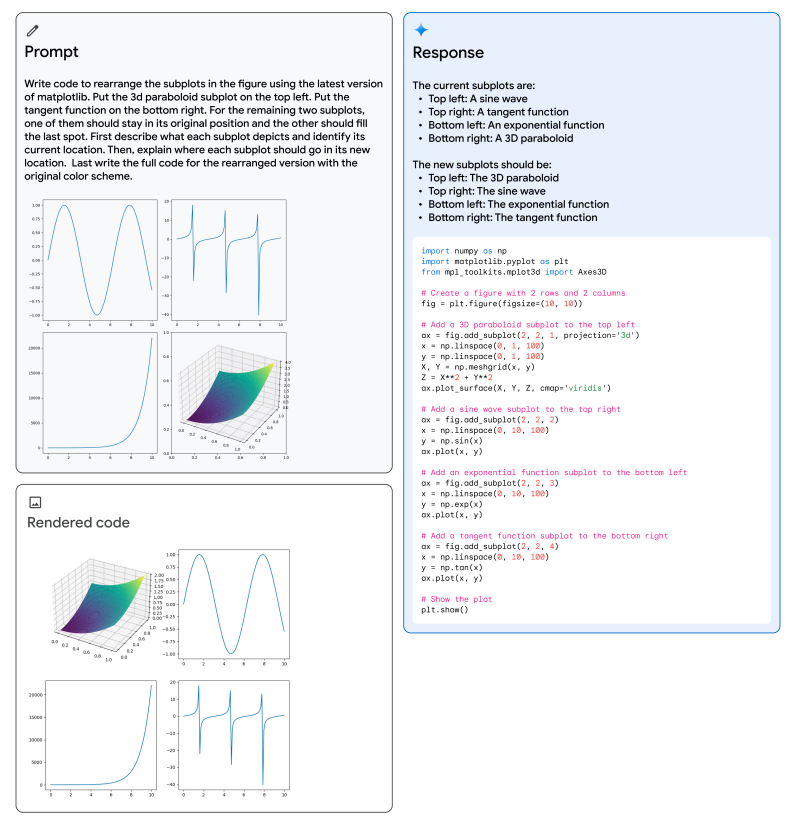
模型输出显示它成功地解决了这个任务,结合了多种能力,包括理解用户图表,推断生成它所需的代码,遵循用户指令将子图放置在其期望的位置,以及关于输出图表的抽象推理。这凸显了Gemini Ultra的原生多模态性,并暗示了它在图像和文本交织序列中更复杂的推理能力。
在它的技术报告中有更多的案例,比如这个读柱状图,然后生成表格。
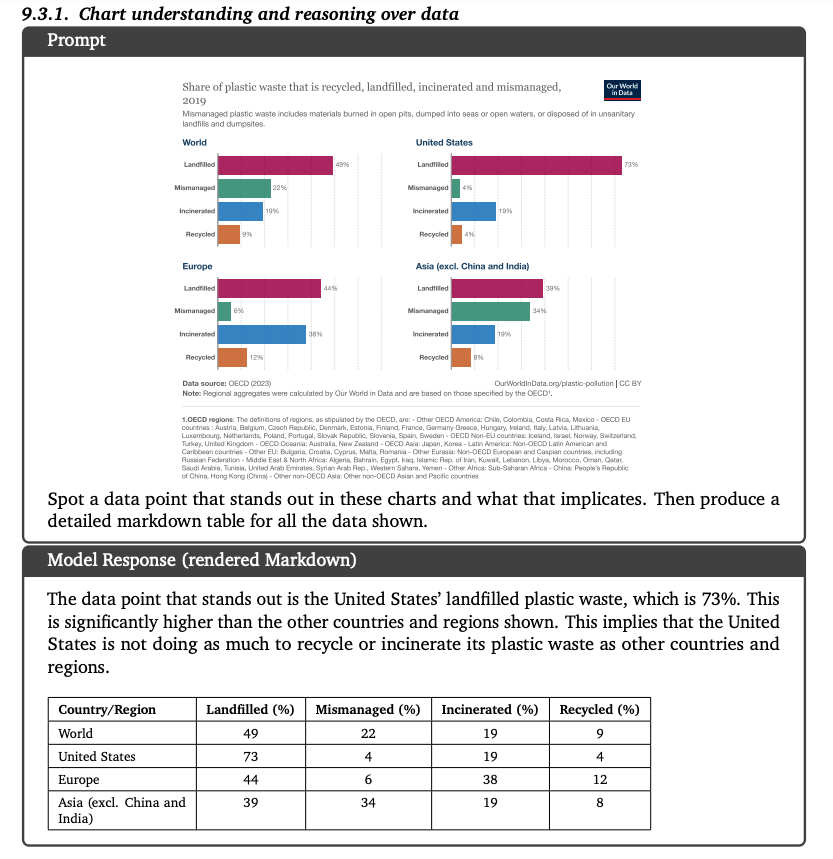
再比如直接生成图文并茂的博客。

图形逻辑推理。

以及读取图片和做数学题。
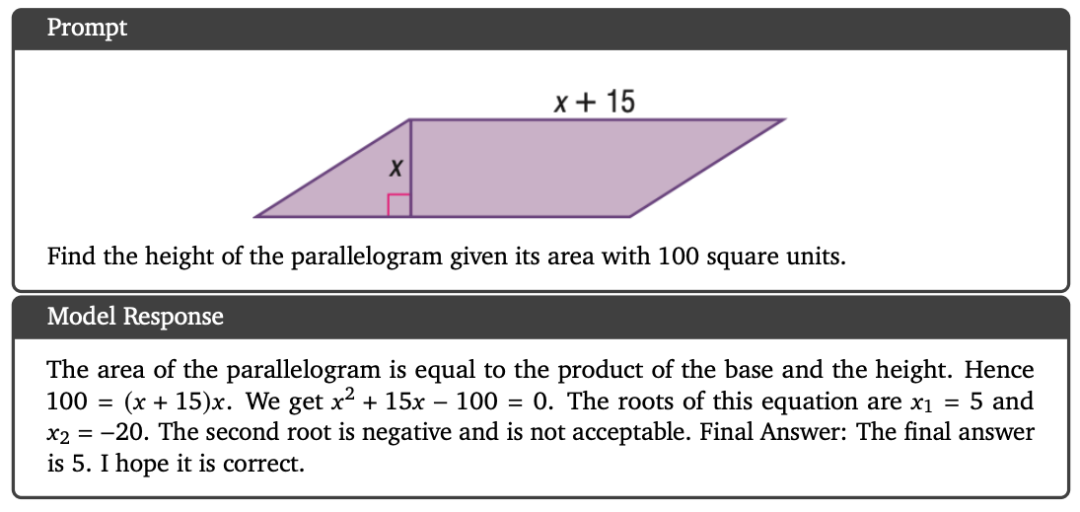
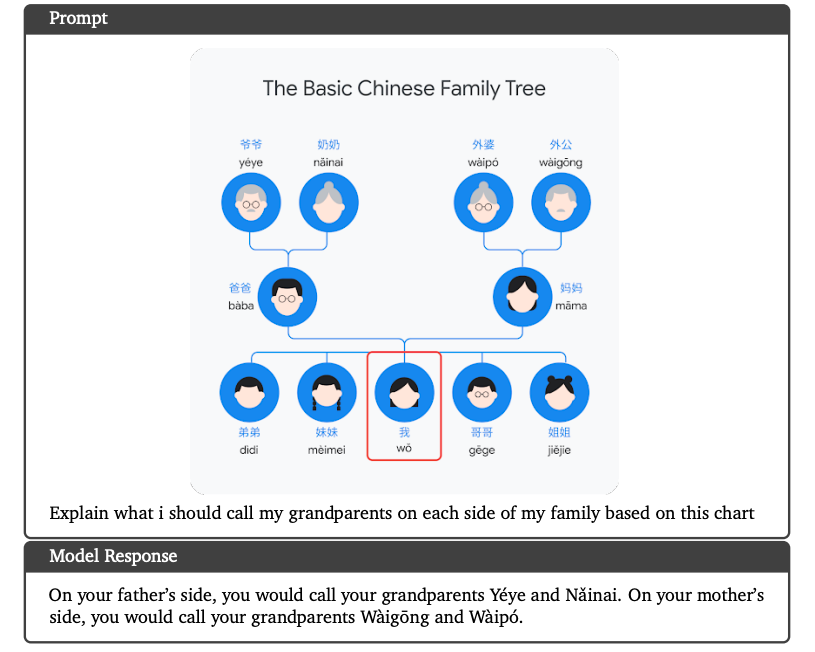
甚至分析中国的家族关系表。
一共有三个版本:
Gemini Ultra — 为高度复杂任务设计的最大和最有能力的模型。
Gemini Pro — 最适合广泛任务扩展的模型。
Gemini Nano — 最高效的机型,适用于设备上的任务。

小结总结,我在GPT4v上测试了Gemini技术报告上的案例,发现Gemini能做到的GPT4v也丝毫不落下风,甚至我觉得GPT4v更强一些。
Gemini Ultra 介绍以及性能性能
Gemini Ultra是三个中最大的,具体参数量没说。
主干还是Transformer,由谷歌的TPU(Tensor Processing Units)加速推理,支持32K的上下文长度。
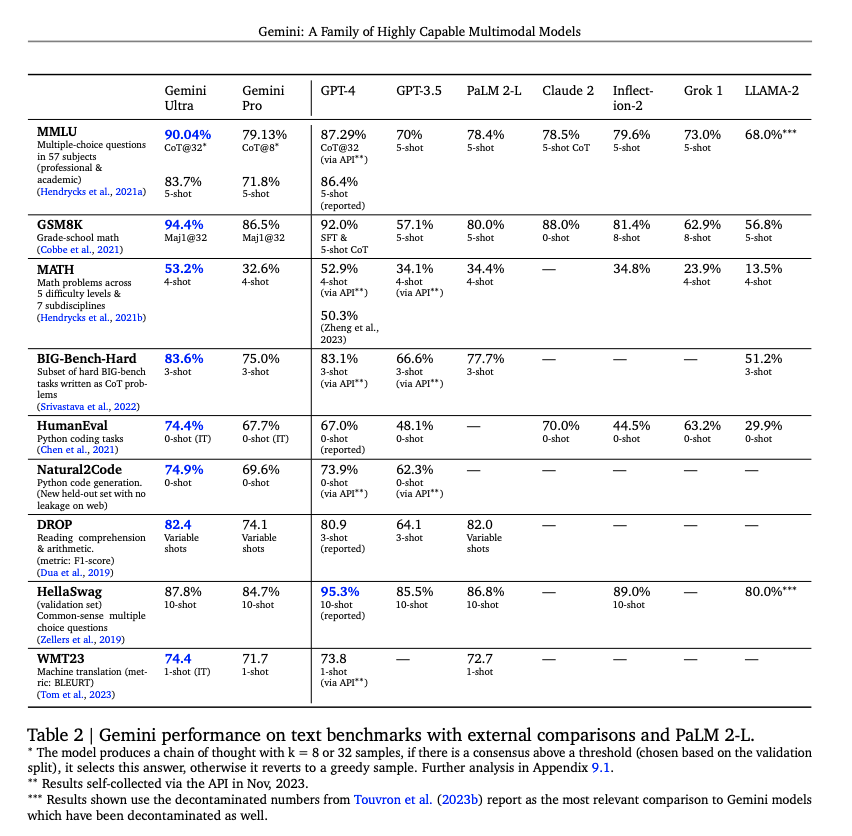
Gemini在各种类型的数据集上都做了测试和对比实验,他们宣称在32个经常被使用的数据集上有30个超过了最强的大模型,也就是GPT4。
其中在MMLU(大规模多任务语言理解)这个数据集上,Gemini Ultra第一次超过了人类,并且他们说在这些测试中,他们没有用OCR对象字符识别技术,证明Gemini的原生多模态的特性。(这个挺有意思的,因为给GPT4输入包含中文的图片确实经常出错,报的错误是OCR识别失败这类型的)。
首先是单纯的文本benchmark测试结果,除了HellaSwag上弱于GPT4,其他都是第一,有意思的是马斯克的Grok也加入了测试,表现平平。
并且可以看到Gemini的Pro版本要强于GPT3.5。
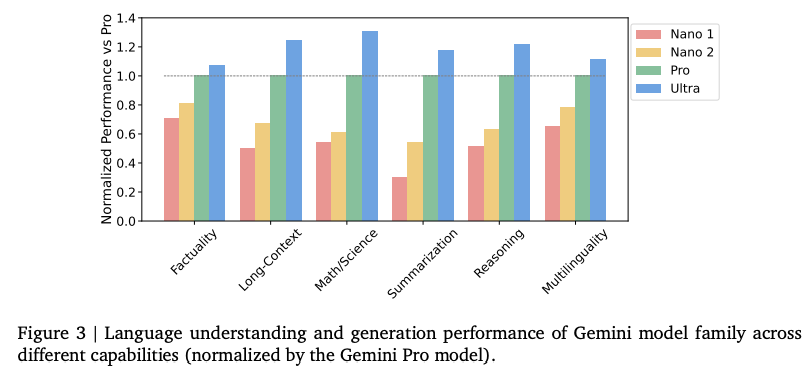
Gemini三兄弟的性能对比,还是参数越大越强。
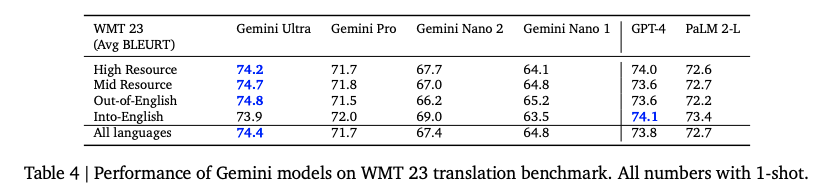
机器翻译性能对比,跟GPT4相差不大,估计已经是暂时的AI极限了。
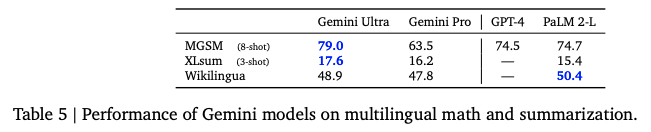
多语言数学和总结测试,GPT4只在MGSM上做过,相差不大,另外两个只能跟PaLM2-L比较,结果相差不大。
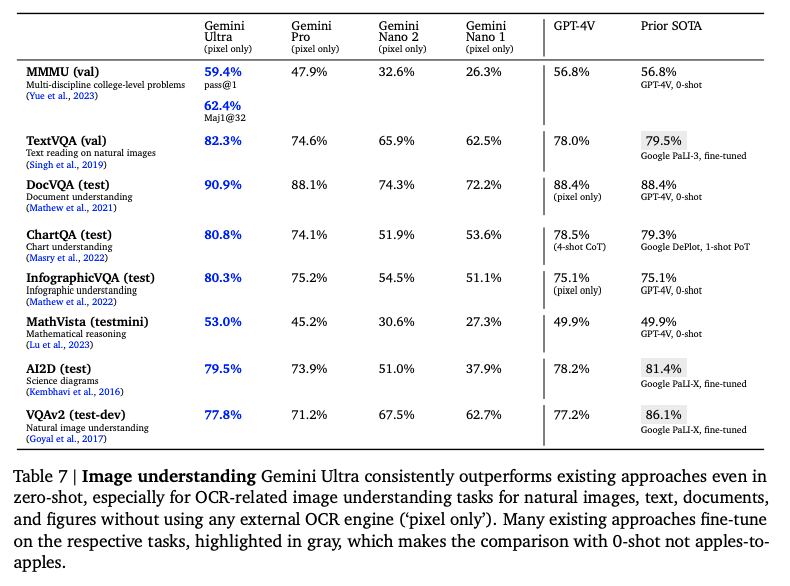
图像理解,遥遥领先(根据提供的案例和GPT4对比测试,我觉得这个不一定准)
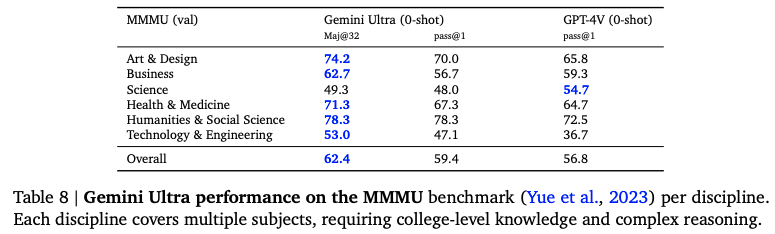
最新的大模型测试数据集上表现很棒
视频理解,遥遥领先,GPT4没有数据
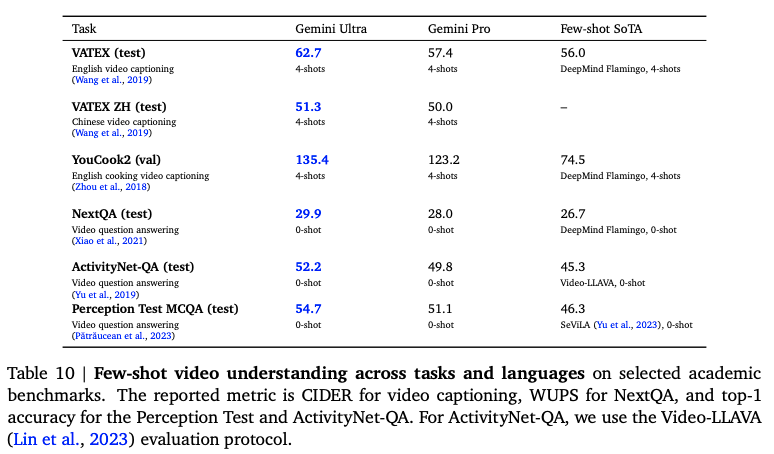
音频理解,用的是Pro和Nano-1,结果是错误率,并且还说了Gemini在处理不常见词汇和专有名词的时候表现的很棒。
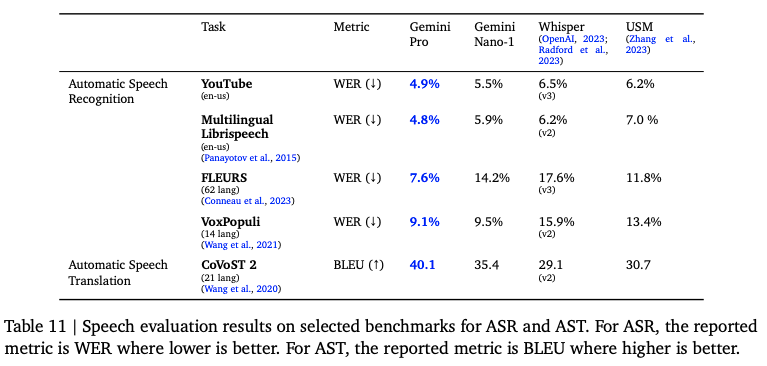
小结总结,Gemini基本上在各种数据类型都很强,不过还没开放使用,只从数据上看确实很强,期待开放个人使用权限。
AlphaCode2发布
主要新增的特性就是跟Gemini Pro结合,在一些代码编写上性能很强。
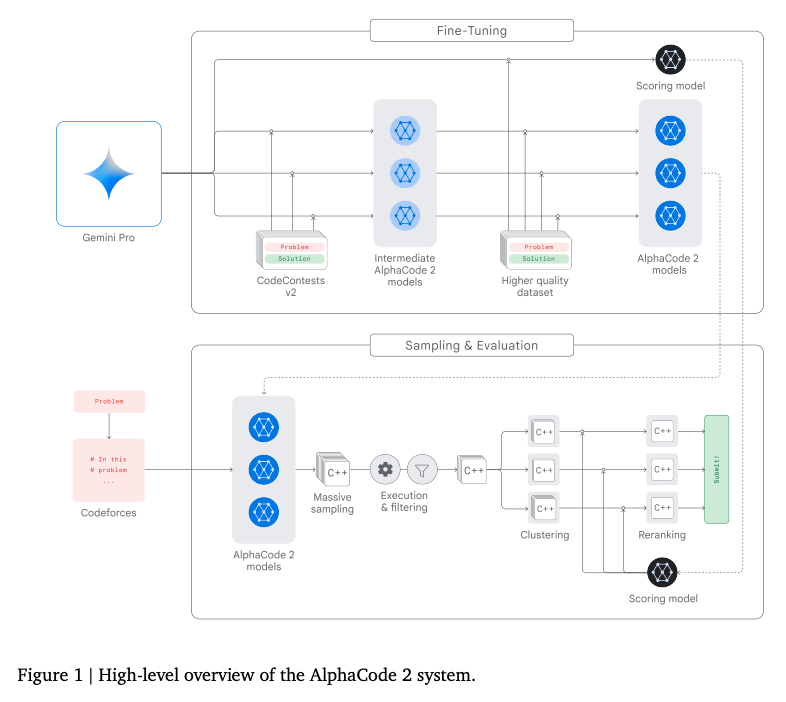
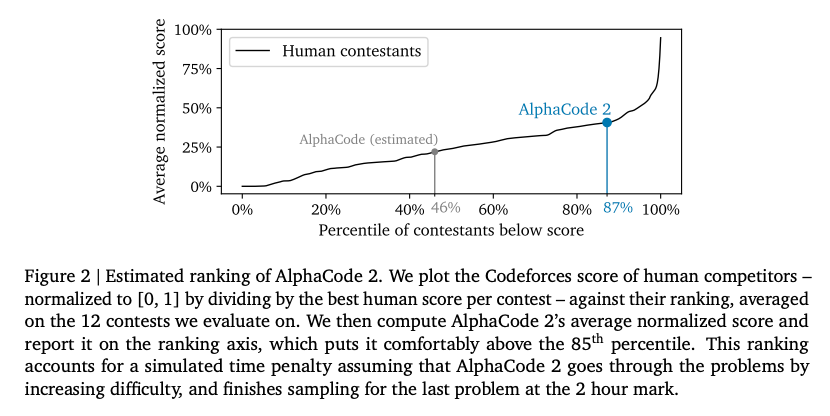
比之前的第一版强了很多
在视频介绍中用一个非常复杂的编程题目考它,结果它非常聪明的用动态编程解决了问题。

复杂推理能力Sophisticated reasoning
这个用的是一个生物学科研的例子,2022年有个工作,一堆人手工的阅读了几千篇论文做了这个论文。

但是距离现在这个领域又多了很多的论文,然后他们用了Gemini,Gemini可以自动去找到大约20万篇文献,并且很快读完进行总结。
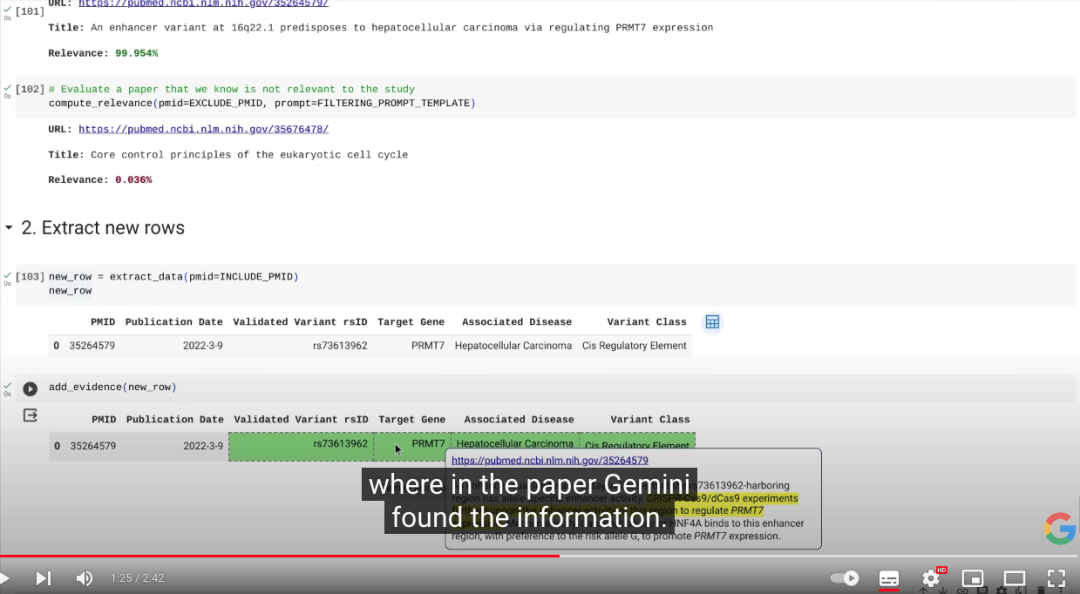
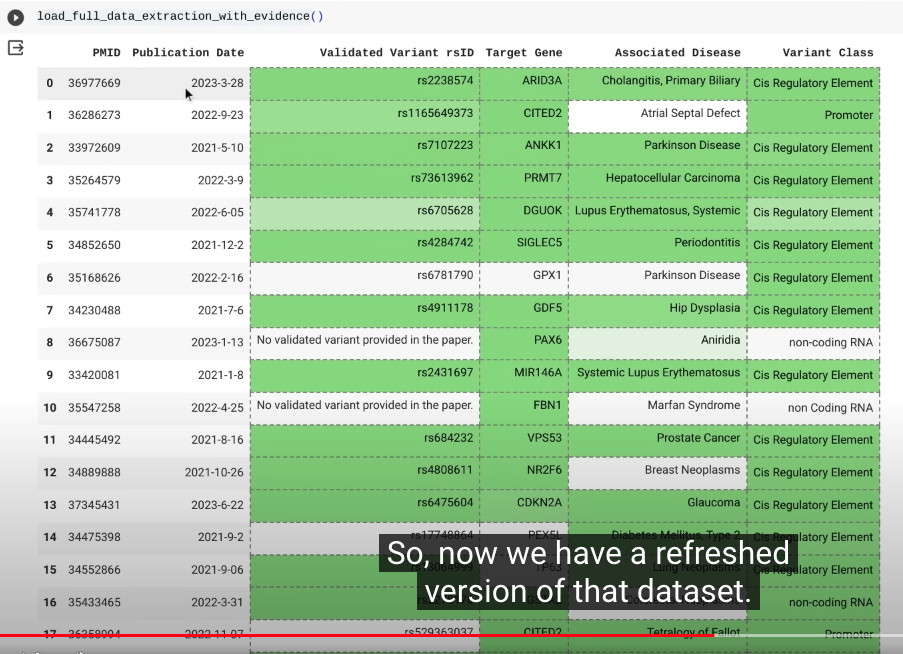
这是更新后的数据集。
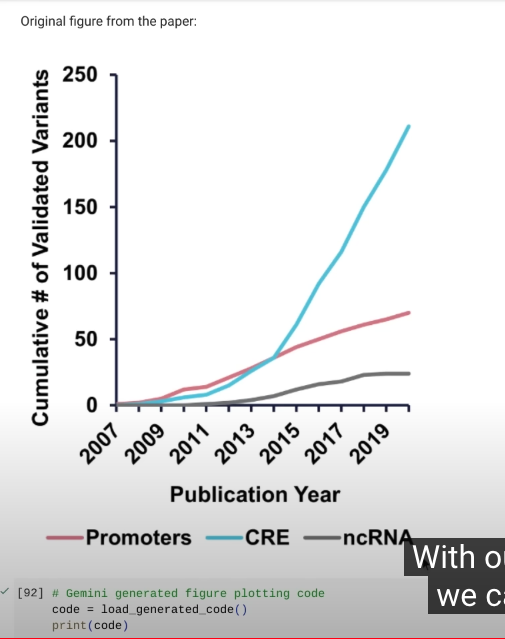
你不用写代码,直接可以理解图片并生成代码给你,你渲染一下就出来新的图了。
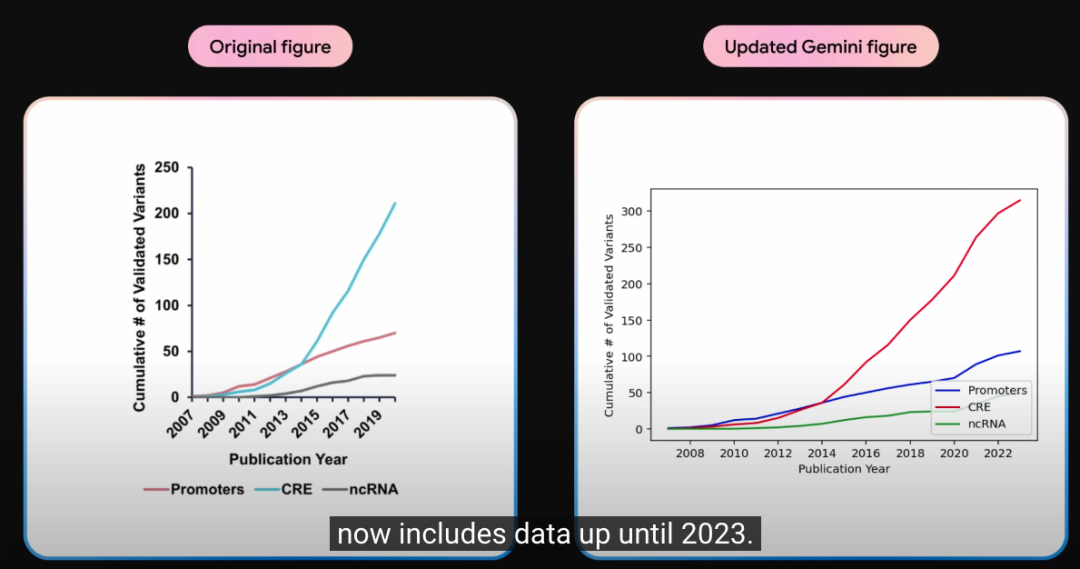
小结总结,我觉得这个功能简直消灭了论文综述这个东西,直接就是最新最全的review,当然了,还是那句话,这只是demo,我之前还想写个综述,现在我还是等等吧。
Anything to Anything
只有一些demo,这个就很酷,可以直接将视频转化成代码,渲染出来类似的东西。

图像理解和推理

多语言理解

没连完线的图也可以正确识别

小结,看上去很牛,特别是可以跟它进行视觉交互式的玩游戏,如果真的这么强,可能戴头盔玩游戏的时代要成真了。
Gemini家族的后续规划
·Gemini 1.0 正在谷歌多个产品和平台上推出。
·Bard将使用Gemini Pro进行高级推理和规划。
·Gemini Pro将支持170多个国家的英语版本,并将扩展支持更多语言。
·Pixel 8 Pro将成为首款使用Gemini Nano的智能手机。
·Gemini将被集成到谷歌的搜索、广告、Chrome和Duet AI等服务中。
·开发者和企业用户将能够通过Google AI Studio或Google Cloud Vertex AI访问Gemini Pro。
·Gemini Nano将支持在Android设备上的任务,并将在Pixel 8 Pro上使用。
·Gemini Ultra将在通过信任和安全检查后不久推出,并计划在明年初向开发者和企业用户推出。
·Bard Advanced将提供接入最优秀模型和功能的新AI体验,以Gemini Ultra为起点。
最后,这就是Google Gemini的主要内容,我的感觉是原生多模态这个出发点非常好,报告的结果也很棒,但是我拿GPT4跟它部分对比,并没有觉得Gemini并没有明显的优势。