先做个广告:需要购买Gemini帐号或代充值Gemini会员,请加微信:gptchongzhi
大家好,我是知白。一个专注于输出 AI+ 编程内容的大厂资深程序员,全国最大 AI 付费社群破局初创合伙人及航海教练,关注我一起进步。
推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
上篇文章讲解了如何在国内使用 Gemini 直接进行对话,但是想要使用 Gemini 大模型实现自己的功能如:微信机器人、公众号机器人、飞书机器人等等,就需要我们去了解 Gemini 的 API 接口才行。
为什么要选 Gemini 呢?还不是 Gemini Pro 免费版每分钟支持60个查询,并且可以长期使用。相比于其他不论是国内还是国外的大模型,进行 API 调用都需要收费,从这点来看真的很香。
借助 Gemini API,可以使用文本和图片数据进行提示,具体取决于使用的模型变体。例如,可以通过 gemini-pro 模型使用文本提示生成文本,并使用文本和图片数据向 gemini-pro-vision 模型发出提示。
当前有两个前置条件跟大家说下:
需要先获取到 Gemini 的 API 密钥,这个需要大家自行解决。 需要一个域名,找个不常用的域名后缀一年只需要几块钱。
一、代理配置
Github 项目地址:https://github.com/antergone/palm-proxy
进入到上述网址,使用 Vercel 来进行快速部署。

进入到 Vercel 中,可以直接使用默认项目名,点击创建。

部署成功后,点击跳转到大盘。

使用自己的域名也很简单,按照如图所示到 IP 控制台上进行配置即可。这里以腾讯云为例,选择添加记录,填充内容如下:

在域名设置完成后,将该域名填入即可。

完成后,我们就可以基于该域名在国内进行调用 Gemini 的 API 接口了。
二、Gemini API 调用
我们要使用自己的域名进行接口转发,所以只能使用 Gemini 的 API 接口各个 URL 进行调用,无法使用官方封装好的各语言工具包。
以下代码我们以 Python 语言为示例进行调用。
一)获取 Gemini 模型列表
获取模型列表接口无须填写任何参数,直接使用 Get 方式调用即可。
import requests
GEMINI_API_KEY = "你的 Gemini API KEY"
GEMINI_API_URL = 'https://你的域名/v1beta/models/gemini-pro:generateContent?key=' + GEMINI_API_KEY
def query():
response = requests.get(GEMINI_API_URL)
result = response.json()
print(result)
if __name__ == '__main__':
query()
返回的内容如图所示,我们可以看到模型的输出和输出的 Tokens 上限,还有模型默认的温度值等等。

二)纯文字输入
执行自然语言处理 (NLP) 任务,例如:文本补全和摘要等,借助 Gemini 来完成。
import requests
import json
GEMINI_API_KEY = "你的 Gemini API KEY"
GEMINI_API_URL = 'https://你的域名/v1beta/models/gemini-pro:generateContent?key=' + GEMINI_API_KEY
def query(input: str):
# 制定的用户内容输入格式和请求头
body = {"contents": [{"role":"user","parts":[{"text": input}]}]}
headers = {"Content-Type": "application/json"}
response = requests.post(GEMINI_API_URL, data=json.dumps(body), headers=headers)
result = response.json()
# 从 API 响应中提取内容部分
candidate = result.get('candidates')[0]
content_parts = candidate.get('content', {}).get('parts', [])
content_text = content_parts[0].get('text', '')
print(content_text)
if __name__ == '__main__':
query("你是谁")
这里是一个基本文字输入调用,类似与我们网页上直接对话一样。输出结果如下:
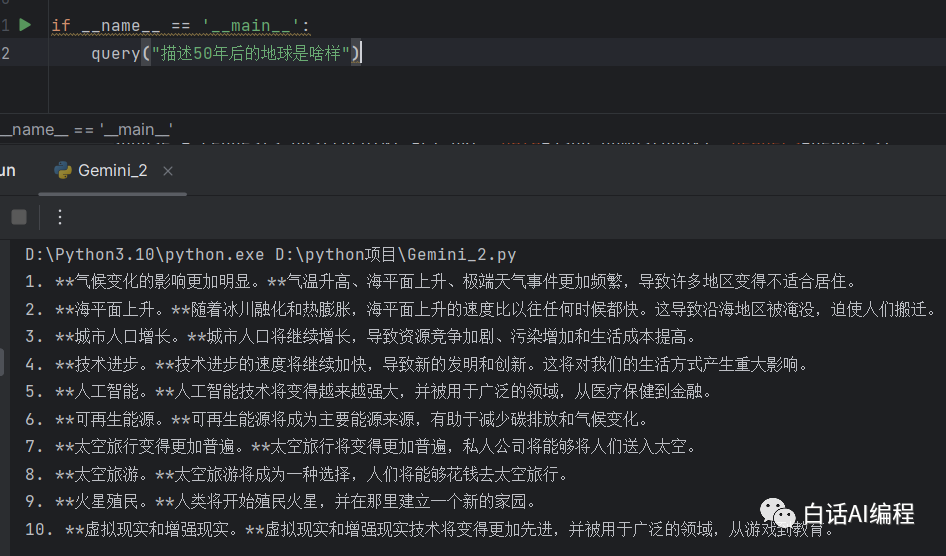
发现 AI 说的很飘,这时候我们需要 AI 输出精确一些就需要调整温度值了。
我们先来讲下 temperature 温度值的定义:
取值范围在 0~1 之间,控制生成文本的多样性。较高的 temperature 值会导致生成的文本更具有创造性和多样性,但是也可能会导致生成的文本不够准确和不可信。较低的 temperature 值则会导致生成的文本更加保守和保险,但是可能会过于死板和缺乏新意。因此,在设置 temperature 值时需要权衡准确性和多样性之间的平衡。
可以将 body 入参调整如下:
body = {
"contents": [{
"parts":[
{"text": input}
]
}],
"safetySettings": [
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_ONLY_HIGH"
}
],
"generationConfig": {
"stopSequences": [
"Title"
],
"temperature": 0.1,
"maxOutputTokens": 800,
"topP": 0.8,
"topK": 10
}
}
当我们将 temperature 调整为 0.1 后再来试试,可以看到输出的内容相对合理且具备一定的可靠性。
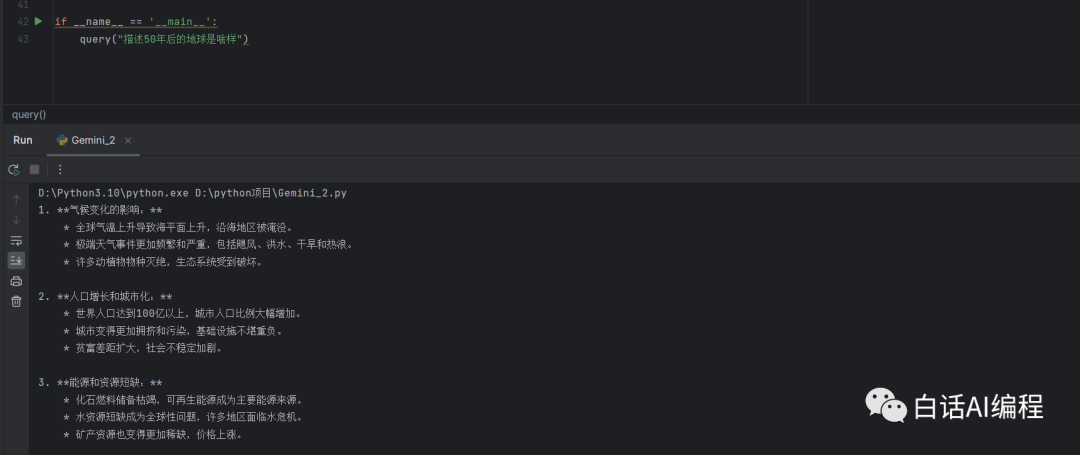
还可以调整其他参数配置,这里我们就不做一一演示了。
三)文本和图片输入
我们还可以向 gemini-pro-vision 模型发送包含图片的文本提示,以执行与视觉相关的任务。例如,为图片添加说明或识别图片中的内容。
使用图片数据的提示受到以下限制和要求的约束。
首先图片必须采用以下任一图片数据 MIME 类型:
PNG - 图片/png JPEG - image/jpeg WEBP - image/webp HEIC - 图片/heic HEIF - image/heif
最多 16 张图片,整个提示(包括图片和文本)不得超过 4MB,包含一张图片的提示往往能产生更好的结果。
import json
import requests
import base64
GEMINI_API_KEY = "你的 Gemini API KEY"
GEMINI_API_URL = 'https://你的域名/v1beta/models/gemini-pro:generateContent?key=' + GEMINI_API_KEY
def query():
# 读取图像文件并转换为 base64 编码的字符串
image_path = "./image.jpg"
with open(image_path, "rb") as image_file:
base64_encoded_image = base64.b64encode(image_file.read()).decode("utf-8")
# 构建POST请求的JSON数据
data = {
"contents": [
{
"parts": [
{"text": "描述这张图片"},
{
"inlineData": {
"mimeType": "image/png",
"data": base64_encoded_image
}
}
]
}
]
}
headers = {"Content-Type": "application/json"}
# 发起POST请求
response = requests.post(url, headers=headers, data=json.dumps(data))
result = response.json()
for candidate in result.get('candidates', []):
# 从 API 响应中提取内容部分创建模型内容,并将模型内容添加到 contents 数组
content_parts = candidate.get('content', {}).get('parts', [])
content_text = content_parts[0].get('text', '')
print(content_text)
if __name__ == "__main__":
query()
其中图片内容是这样的:

看下返回结果,回答的内容还是很精准:

总结
我们这节讲解了三个基础的 API,获取模型列表、纯文字输入、文字和图片输入,大家可以先玩起来。

本文链接:https://google-gemini.cc/gemini_36.html
ChatGPT Plus谷歌Gemini跟ChatGPT哪个好谷歌Gemini 的特点谷歌Gemini Nano如何使用谷歌Gemini模型如何使用谷歌Gemini如何使用GeminiGoogle GeminiGoogle Gemini跟ChatGPT对比Gemini API Key