先做个广告:需要购买Gemini帐号或代充值Gemini会员,请加微信:gptchongzhi
北京时间12.6午夜,本来今天准备早睡了,结果没法早睡。
 推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top

Google发布了它憋了很久出的多模态大模型-Gemini,剑指Openai的GPT4-turbo,甚至在测评中只选取了GPT4-turbo作为唯一的测评对象,这是Google对Gemini的横幅:“Gemini 简介:我们最大、能力最强的人工智能模型”,那我们一起来看看谷歌的这个Gemini究竟是什么模样。
Gemini介绍
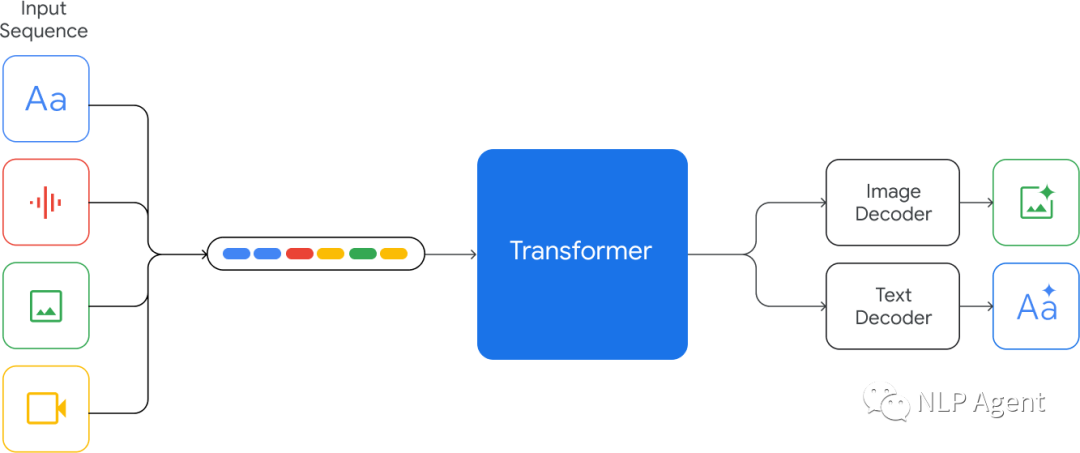
Gemini 是整个 Google 团队大规模协作努力的成果。它是从头开始构建的多模态,这意味着它可以概括和无缝地理解、操作和组合不同类型的信息,包括文本、代码、音频、图像和视频,也就是说Gemini是从架构的最底层一层一层的搭起积木盖起了Gemini,从中协调了Google各产品技术团队的技术产出。

Gemini推出了三种型号:
Gemini Ultra——Gemini最大、最有能力的模型,适用于高度复杂的任务,对标GPT4-turbo,预计在明年初推出上市。
Gemini Pro——可扩展各种任务的最佳模型,对标GPT3.5-turbo-1106,现已更新到Bard,可免费使用,API将于12.13日上市提供给开发者和企业用户。
Gemini Nano——最高效的设备端Gemini模型,作为移动端或边缘计算的本地LLM,Nano 的两个版本,参数分别为 1.8B (Nano-1) 和 3.25B (Nano-2),分别针对低内存和高内存设备,采用 4 位量化进行部署。适配于Google前段时间推出的Piexl 8 Pro手机上,看了眼手机价格,1699刀。
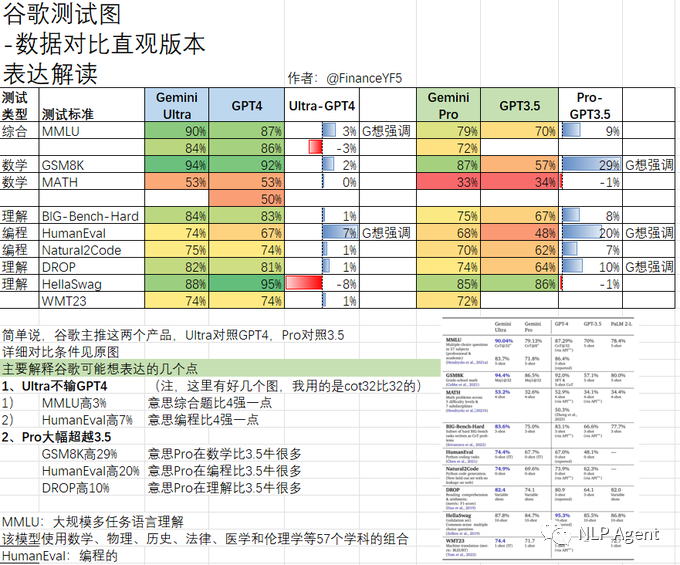
Gemini性能对比
Gemini在文本的数学和编程任务上表现出色,无论是Ultra版本或是Pro版本,都大幅领先于相同level的Openai系列LLM,可以说Gemini和GPT不相上下、平分秋色,是Openai迄今为止最大的竞争者,当然也威胁着Openai背后的微软,最近总是在搞些不痛不痒的动作。
多模态能力
文本
Gemini能够筛选大量科学文献以找到与特定研究相关的论文,示例中对2021年以来新增的200,000篇论文进行筛选。Gemini被用来阅读这些论文并从中提取关键数据,并且在提取的数据上添加注释,说明信息是从论文的哪个部分获取的。最后Gemini从200,000篇文献中筛选出250篇,这仅仅花费不到一个小时,检索到高相关性的论文,远超目前各家Long context的性能,并且能够给出来源。
编码
Gemini可以理解、解释和生成流行编程语言(如 Python、Java、C++ 和 Go)中的高质量代码。Gemini Ultra 在多个编码基准测试中表现出色,包括 HumanEval(评估编码任务性能的重要行业标准)和 Natural2Code。
图像
对于含有文本内容的图像识别,Gemini Ultra 的性能优于以前最先进的模型,能够无需OCR的帮助,自己原生具备识别图像中文本内容的能力。
对于图像像素内容的理解,Gemini也展示出了非常震撼的能力。

Case1:全流程的识别用户动作,并实时的语音交互。
示例:用户在纸上全程手绘出一只鸭子,从线条、轮廓到最后成型的鸭子,Gemini都能实时的和用户进行对话,告诉用户这是曲线、动物轮廓、鸭子,和用户深度的语音交流反馈,不仅语音延迟低到可忽略不计,而且Gemini的声音和语音都像是你的一位老朋友在和你沟通那般亲切,文字语言没有一种冷漠的机械感。

Case2:用户和Gemini进行猜国家的游戏互动,Gemini给出了某个国家的特色,用户在地图上指出即可验证回答的是否正确。
示例:Gemini用语音的方式告诉用户某个国家的特色有袋鼠、考拉等,猜猜是哪一个国家?用户在地图上手指指向澳大利亚,Gemini立刻就回答:”Bingo!“,你答对啦!

Case3:用户和Gemini玩纸团在哪个杯子里的游戏,很像人们平常玩的游戏。
示例:用户将一个纸团放在了某个杯子下,随后快速的移动杯子,试图混淆在三个杯子中,但最后蒙不了Gemini,Gemini同学准确地识别出了盖住纸团的杯子,仿佛在说:就这?

Case4:Gemini创意发挥的将物品结合起来。
示例:用户提供两个彩色线球,需要Gemini发挥想象,将他们织成一个动物形象的线球,Gemini给出了一个粉色猪头蓝耳朵的线球玩偶,funny。
音频

Case1:Gemini根据手绘的图像来生成相应风格的音频。
示例:用户在纸上手绘了一个吉他,Gemini立刻生成了一首吉他的曲子音频;然后用户继续手绘了鼓,Gemini也立刻更新了音频,融入了鼓点;最后,纸上出现了一一棵热带植物棕榈树,Gemini也心领神会,立刻将音频更新为热带海滩风格的音乐,而且整个过程交互体验非常棒,perfect!
视频

Case1:考考Gemini知不知道手机里播放的这段视频是什么?看看Gemini的爱好有没有看电影呢
示例:用户手机播放了一段来自电影《黑客帝国》的”子弹镜头“时间片段,视频还没放完,Gemini已经懂了,精确的识别出了这个视频片段的动作,这个能力秒杀微软AI Search中的视频搜索的,不客气地说,微软的Video Search是残废了。
总结
Gemini展现出来的多模态能力尤为亮眼,在最近一众图像、视频的AI模型中可以说鹤立鸡群,多模态给予了大模型视力和听力,更具备人类的生物特征,看看Openai方面会有什么动静?GPT5?拭目以待。