先做个广告:需要购买Gemini帐号或代充值Gemini会员,请加微信:gptchongzhi
早上一起床,铺天盖地都是 Gemini 的新闻,从5月份 Google IO 大会就开始宣传,拖了大半年,终于出来了。
 推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
Gemini 的意思是双子座,为什么起这个名字呢?是因为当时 Google 有两拨人在搞大模型,Google Brain 和 DeepMind,当时两拨人有点像是赛马,Google Brain 搞出了 Bard, DeepMind 搞了 sparrow, Chinchilla,当然也搞了一些 AlphaFold,AlphaCode 等。总之 Google Brain 更偏实际应用, DeepMind 还是偏研究一点。但是 3月14日发布的 GPT-4 让 Google 瞬间慌了,咱也别内部赛马了,赶紧和 OpenAI 赛一赛。所以当时决定让两个团队合作,这两个团队的合并就被称为 Gemini (双子座),同时双子座计划也是美国第二个载人航天计划,计划的目标是为更先进的太空旅行积累技术,为阿波罗登月计划奠定了坚实的基础,所以 Gemini 的名字也代表了谷歌对人工智能的探索和对成功的渴望。
Google 其实也挺不容易,说实话 Transformer 是 Google 搞出来的,现在大模型都是基于 Transformer 架构的,结果在整个2023年,Google 都被 OpenAI 按在地上摩擦。
Google 就有点像少林寺,当年培养了一个小伙计张三丰,也就是目前 OpenAI 的首席科学家 Ilya。结果张 ·Ilya· 三丰 跑出去搞了个武当派(OpenAI)。
这少林寺能忍,这江湖我说了还算不算了?所以这场仗必须得拿下,今天就是少林寺(Google)对武当派(OpenAI)的亮剑时刻。

来看一下亮的剑怎么样。
先看下效果
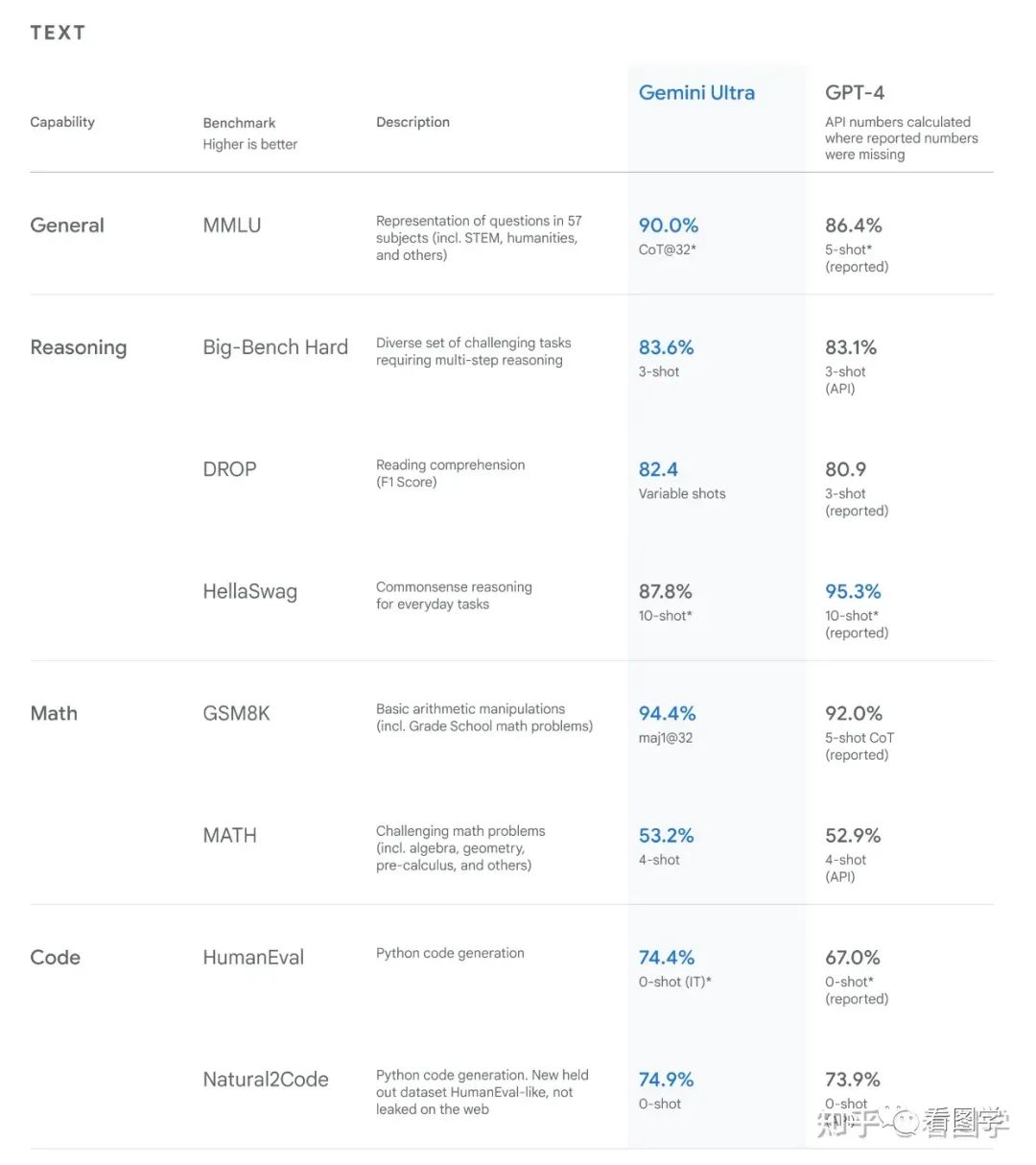
不能说是遥遥领先,但是也是一马当先了。测评比较多,就不细说了,只挑几个有意思的点。
Google 在 report paper 里面明确说了,测试数据全部从训练数据中剔除,所以都没有见过原题,但是可能见过类似的题目。
MMLU 这份数据集合,请每个领域的专家来做,得分是 89.8 分。GPT4 的得分是 86.4,采用 Cot@32 可以达到 87.29 分。Google 采用 Cot@32 可以达到 90.04 分,首次超过人类。但是这里有两个点没说明,一个是没有采用 Cot@32 有多少分?在一个 Gemini 的参数量只公布了 Nano 版本的,这个测试是 Ultra 版本,到底多大还不太清楚。猜测可能的模型大小就是MMLU 刚好超过人类效果的模型大小。可能会偏大一点,但是我有钱和 TPU, 咱就是要比人类要好。
再一个 Google 为了测试代码能力,在 AlphaCode 的基础上,换成了 Gemini 作为基座,公布了 AlphaCode 2, 然后去 codeforces 网站上参加竞赛,结果是超越了 85% 的考生。codeforces 是俄罗斯的一个 online judge 的网站,搞 ACM 和 IOI 的可能都知道,可以理解为一个更高难度的 leetcode,里面都是些算法大神,比如楼天城,Petr,rng_58 都曾经在这个网站上奋斗过。我之前上学时还刷过一段时间,目前看我肯定是被 Gemini 吊打。
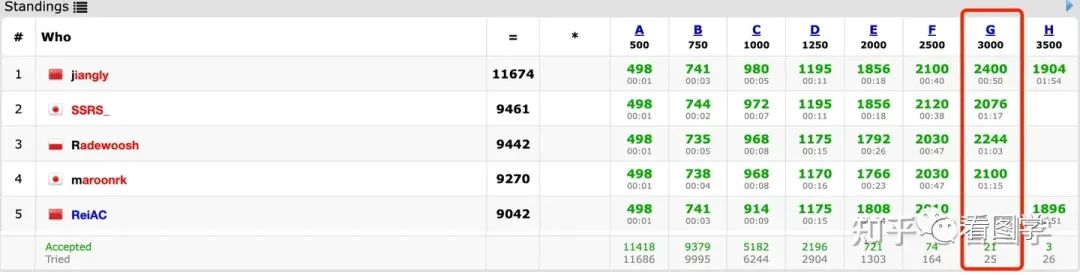
若还特意去看了下 Gemini 做的一个题目,链接为:https://codeforces.com/problemset/problem/1810/G
这场批赛一共有12000多人参加,这个题目只有25个人答对了。属于3200分段的题目,这个网站上3200分以上的人目前一共有22个人,是一个很难的题目。而 GPT-4 在某些 1000 分段的题目上做的还不好,从这个角度上看,Google 在编程和推理上可能有所突破。
怎么做的
然后核心技术,Google 并没有讲太多。大厂现在都这个德行。
这次公布了3个版本
Ultra
TPU 云服务,出于安全考虑,明年才能给大家用。
猜测可能是个千亿模型
Pro
通用版本。
猜测是个百亿模型。30-80B
Nano
1.8B/3.2B 4-bit quantized
可以运行在移动设备上, Pixel 8 Pro*
所以说 Google 的野心还挺大,从云端到手机端,从大到小都给你准备好了。
下面是一些训练和数据的细节。
训练时候用了多模态和多语言
最大长度为32k
使用了SentencePiece tokenizer, 而且经过验证,在更多的数据集上训练SentencePiece tokenizer,能提升模型效果
训练数据混合权重是在小模型上做消融实验得出来的,DoReMi 的思路,但是分阶段进行,在每个阶段会改变数据的混合比例,比如在训练末期会增加领域相关数据的权重。
Google 的训练的基建是真的强,有一些原理和技术我还没看论文,不敢瞎说,比如“TPUv4 accelerators are deployed in “SuperPods” of 4096 chips, each connected to a dedicated optical switch, which can dynamically reconfigure 4x4x4 chip cubes into arbitrary 3D torus topologies in around 10 seconds (Jouppi et al., 2023). ”
一个有意思的训练细节是 Google 没有采用保存 checkpoint 的方法,而是直接在训练过程中将模型状态都在内存里复制了一份,所以任何硬件故障都可以快速恢复,空间换时间。
粗看下来呢,Google 在这次 AI 竞赛中,成功挺过了第一轮淘汰赛,但是保不齐明年 3月14 GPT5可能要出了,还得加油。
目前 Bard 据说已经接入 Gemini 了,我去“弱智吧”找几个问题测测。
觉得写的还可以,点击下方关注
历史文章合集:
手慢无!陆奇《新范式 新时代 新机会》完整版演讲PDF ChatGPT调研综述。哈工大最新出品! 我想学大模型,应该从哪个模型开始?LLaMA生态家谱整理和分析 如何把让大模型处理一本书?(更长的文本) 如何根据模型参数量估计需要的显存? 大模型开源SFT训练数据整理 OpenAI刚发布大杀器功能,无数AI创业公司的方案推倒重来 只有中东富豪的钞能力才能打败OpenAI?Falcon模型介绍 《大规模预训练语言模型方法与实践》完整版分享 国内大模型测评现状
大模型推理加速:看图学KV Cache
如何在HuggingFace上开源自己的模型?
阿里最近为什么疯狂卷开源大模型?
万水千山总是情,点个“在看”行不行👇