先做个广告:需要购买Gemini帐号或代充值Gemini会员,请加微信:gptchongzhi
继Gemini 1.0 发布后,全新的 Gemini 1.5 家族强势登场,带来多模态理解能力的代际飞跃。Gemini 1.5 不仅仅是简单的升级,它代表了 AI 领域一次根本性的转变:从处理碎片化信息到理解和整合数百万token的上下文,从单一模态到多模态的融合,从有限的应用场景到无限的可能性。
 推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
![]()
Gemini 1.5 家族包含两个全新成员:
![]()
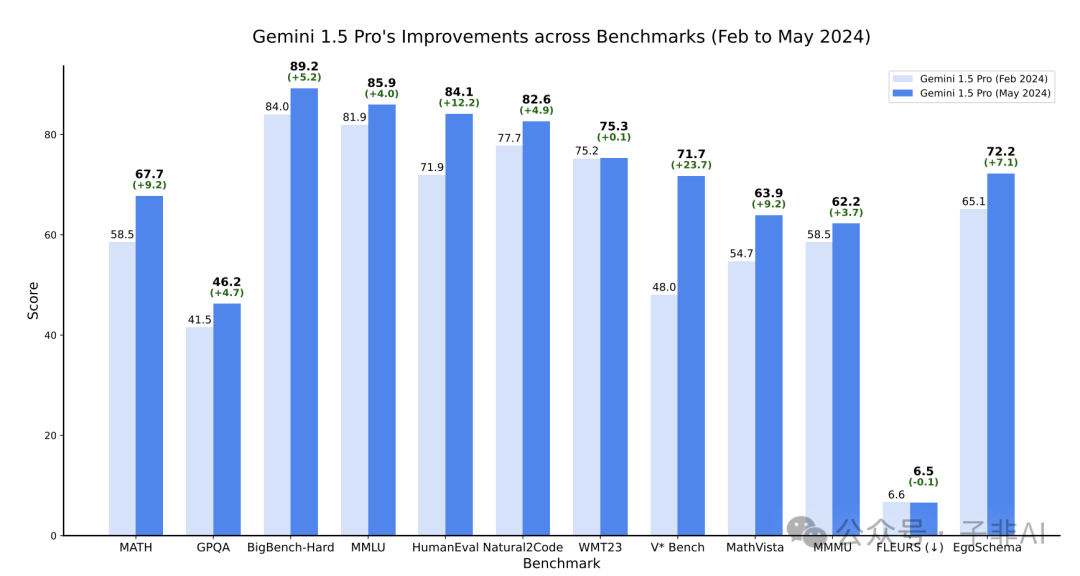
图 | Gemini 1.5 Pro(2024年5月)与初始版本(2024年2月)在多个基准测试中的比较。最新的Gemini 1.5 Pro在所有推理、编码、视觉和视频基准测试中都有所改进;音频和翻译性能保持中立。请注意,对于FLEURS基准测试,较低的分数表示更好的性能。
Gemini 1.5 Flash: 更加轻量级的版本,旨在提供更高的效率和更快的推理速度,同时将质量下降降至最低。
Gemini 1.5 的核心突破在于其强大的长上下文理解能力,能够回忆和推理来自至少 1000 万个标记的细粒度信息。这相当于能轻松处理近五天的音频、完整的长篇小说、大型代码库,甚至是超过 10 小时的视频!
![]()
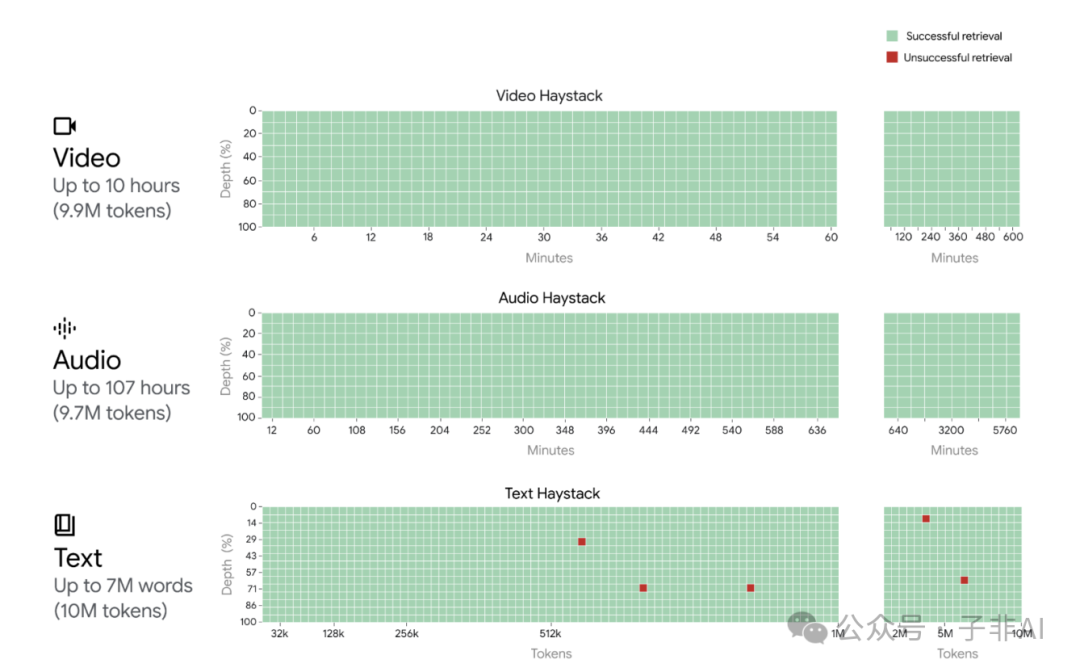
图 | Gemini 1.5 Pro 在所有模态中实现了接近完美的“针”召回率(>99.7%),最多可达100万个“干草堆”令牌。即使将文本模态扩展到1000万个令牌(大约700万个单词);音频模态扩展到970万个令牌(最多107小时);视频模态扩展到990万个令牌(最多10.5小时),它仍然保持这种召回性能。x轴代表上下文窗口,y轴代表给定上下文长度的针深度百分比。结果用颜色编码表示:绿色表示成功检索,红色表示未成功检索。请注意,所有模态的性能都是基于之前报告的2月份的Gemini 1.5 Pro版本获得的。
这项突破性进展将如何改变 AI 格局?让我们深入探究 Gemini 1.5 的核心技术和能力。
模型架构:稀疏混合专家与在线蒸馏
Gemini 1.5 家族的两个成员采用了不同的模型架构,以满足不同的应用需求:
Gemini 1.5 Pro: 基于稀疏混合专家(MoE)Transformer 架构,能够在处理海量信息时,只激活与当前任务相关的参数子集,从而大幅提高效率。这种“按需分配”的计算方式,使得 Gemini 1.5 Pro 即使面对百万级token的上下文,也能保持高效的运算速度和精准的理解能力。
Gemini 1.5 Flash: 采用了更加轻量级的 Transformer 解码器模型,并通过在线蒸馏技术从 Gemini 1.5 Pro 模型中学习知识。在线蒸馏技术可以将大型模型的知识压缩到小型模型中,从而在保证一定性能的同时,大幅降低模型的规模和计算成本。
除了模型架构的创新,Gemini 1.5 还得益于 Google 强大的训练基础设施和丰富的数据集。Gemini 1.5 模型是在多个分布于多个数据中心的 Google TPUv4 加速器 4096 芯片 pod 上,以及各种多模态和多语言数据上训练的。
服务效率和延迟:快如闪电,高效便捷
对于实际应用来说,除了模型的理解能力,服务效率和延迟也是至关重要的指标。Gemini 1.5 模型在所有上下文长度下都展现出高效率和低延迟,尤其是在处理长文本、音频和视频时,优势更加明显。
![]()
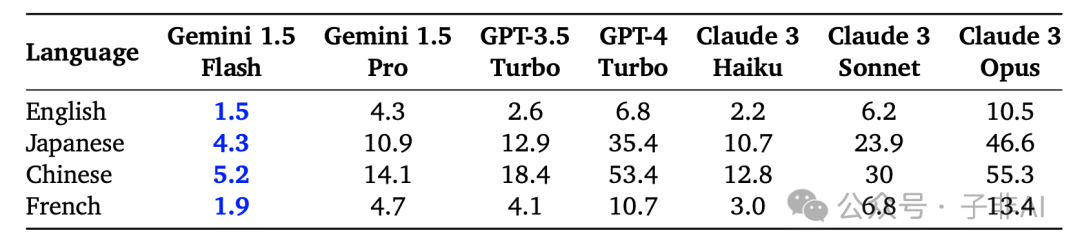
在对英语、日语、中文和法语的查询测试中,Gemini 1.5 Flash 的输出生成速度都是最快的,甚至比 Claude 3 Haiku 快 30% 以上。Gemini 1.5 Pro 的生成速度也比 GPT-4 Turbo、Claude 3 Sonnet 和 Claude 3 Opus 快,展现出强大的竞争力。
百万token上下文,开启 AI 认知新边界
Gemini 1.5 Pro 百万级token的上下文理解能力,为 AI 认知解锁了全新边界。它不仅能够处理过去难以想象的海量信息,更重要的是,它能够理解和整合这些信息,并进行多层次推理和知识整合,从而展现出更加接近人类的认知能力。
![]()
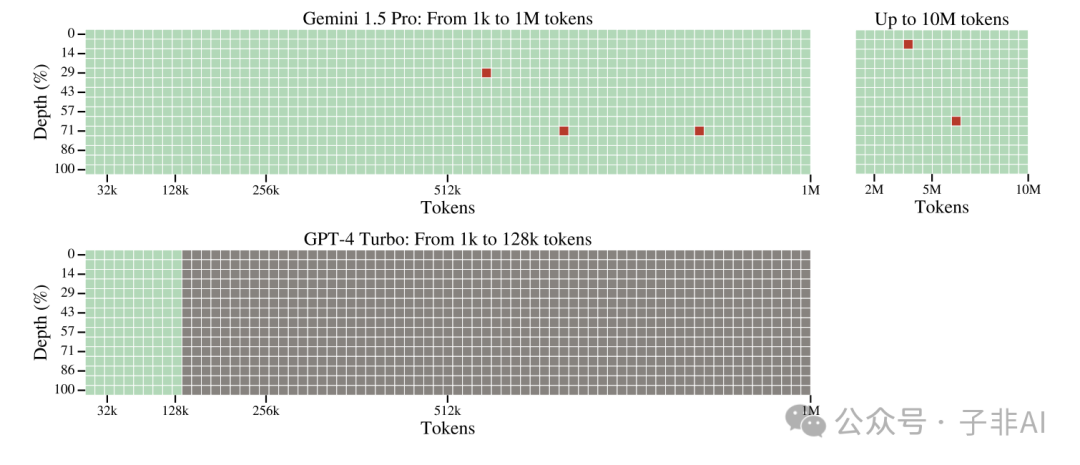
图 | 该图将Gemini 1.5 Pro与GPT-4 Turbo在文本“大海捞针”任务中进行了比较。绿色单元格表示模型成功检索到了秘密数字,灰色单元格表示API错误,红色单元格表示模型响应中不包含秘密数字。顶部行显示了Gemini 1.5 Pro的结果,从1千个令牌到100万个令牌(左上),以及从100万个令牌到1000万个令牌(右上)。底部行显示了GPT-4 Turbo在支持的最大上下文长度128千个令牌的结果。
在 "大海捞针 "测试中,Gemini 1.5 Pro 的强大召回率证明了其卓越的信息检索能力。但这仅仅是 Gemini 1.5 Pro 能力的冰山一角。更令人惊叹的是,它能够在长上下文中进行推理和知识整合,解决更加复杂的任务。
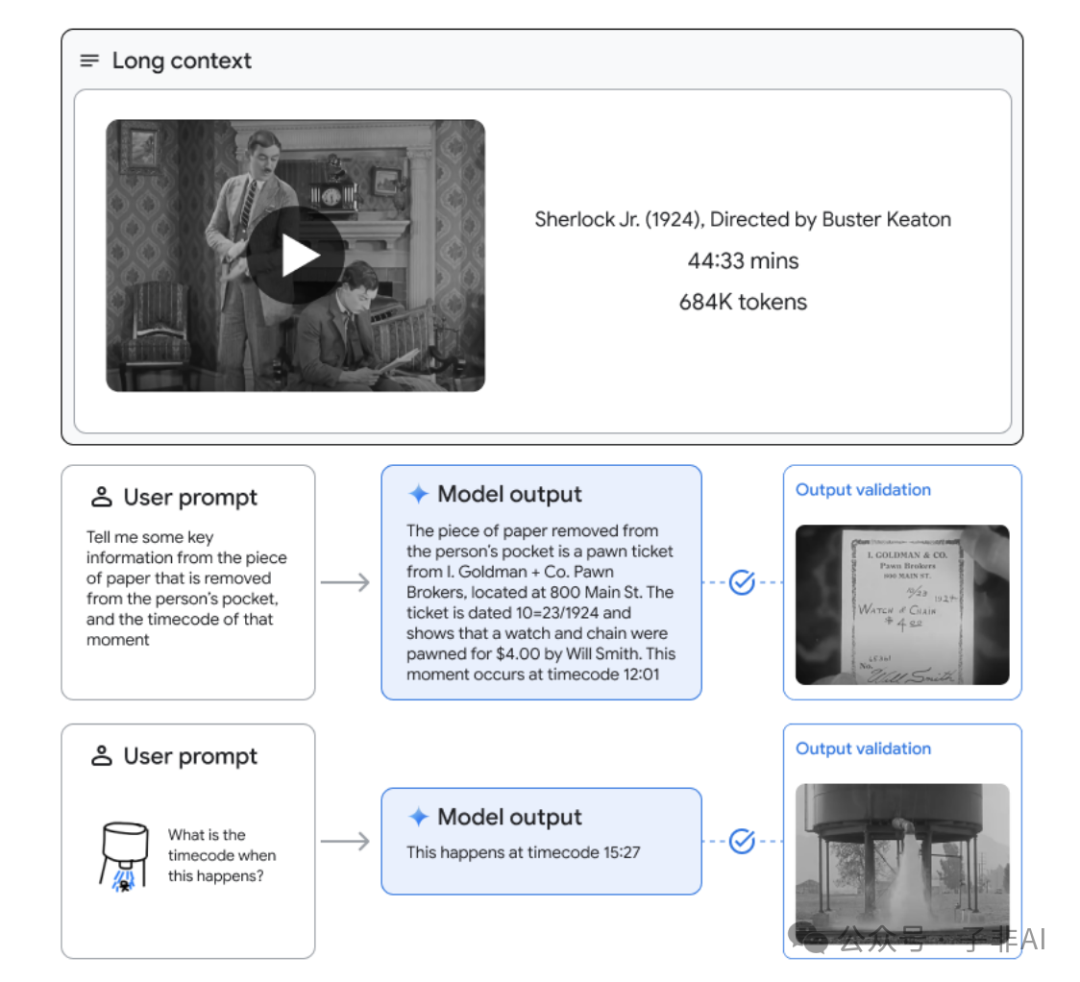
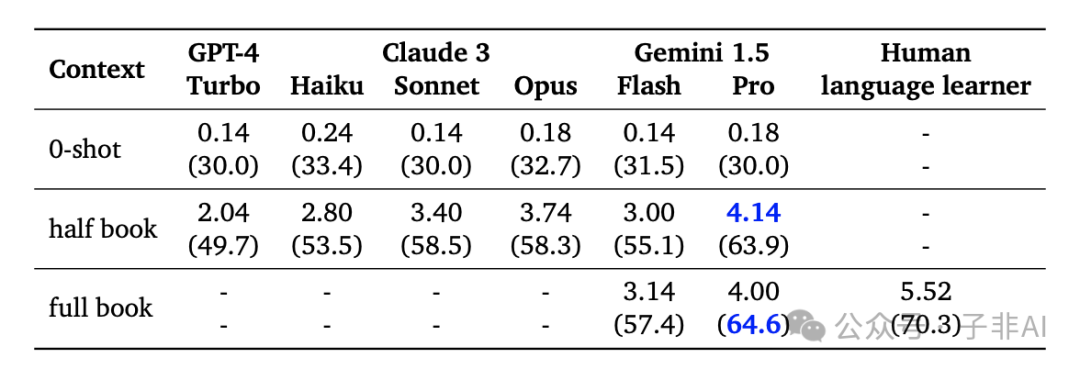
例如,Gemini 1.5 Pro 能够分析整篇《悲惨世界》并回答关于人物关系、情节发展和主题思想等复杂问题,而不仅仅是提取单个事实或细节。它还能理解一部 45 分钟电影的内容,并根据你的指令,精准定位到特定场景和时间戳,并提供相应的文字描述。
上下文语言学习,低资源语言的福音
语言是人类文明的基石,但世界上还有许多语言缺乏足够的数字化资源,导致机器翻译和语音识别等技术难以应用。Gemini 1.5 的出现,为解决这一难题带来了新的希望。
![]()
Gemini 1.5 展现出强大的 in-context learning 能力,能够在推理阶段仅凭上下文提供的资料学习新的任务。即使是像卡拉曼语这样只有不到 200 人使用的低资源语言,Gemini 1.5 Pro 也能仅凭一本语法手册,就学会翻译和转录。
更令人惊喜的是,Gemini 1.5 Pro 能够扩展 in-context learning 的规模,随着上下文提供的样本数量增加,翻译质量也会不断提高。这为低资源语言的机器翻译和语音识别带来了新的可能性,也为保护语言多样性做出了贡献。
核心能力全面提升,更智能的多模态 AI
除了长上下文理解能力和上下文语言学习能力,Gemini 1.5 Pro 在数学、科学、推理、编码、多语言和指令遵循等核心能力上也取得了全面的提升,展现出更加强大的智能。
在 Hendrycks MATH、GPQA、HumanEval、Natural2Code 和 MGSM 等一系列基准测试中,Gemini 1.5 Pro 的表现均超越了之前的版本,甚至在多个测试中超过了最先进的模型 Gemini 1.0 Ultra。
例如,在 Expertise QA 中,Gemini 1.5 Pro 的表现令专家们印象深刻。它能够准确回答需要专业知识的复杂问题,并提供完整、信息丰富的答案,展现出强大的知识储备和推理能力。
挑战数学难题,数学能力再升级
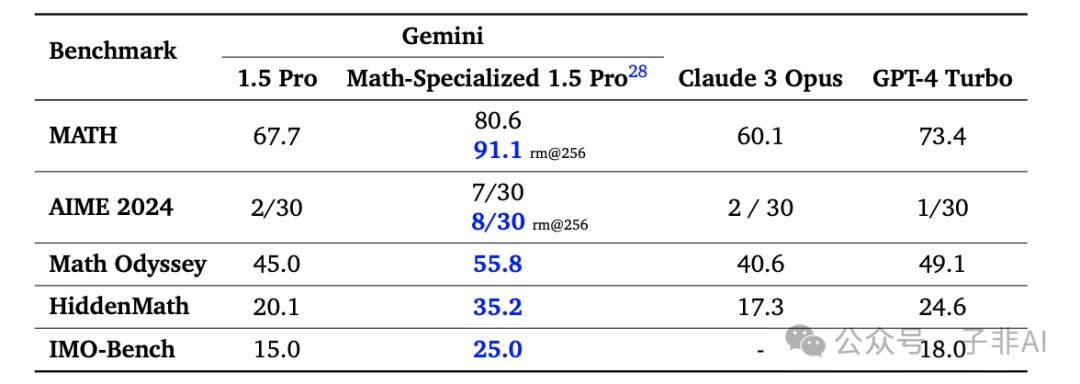
数学推理一直是人工智能研究的难点,而 Gemini 1.5 在数学能力上取得了突破性进展。 为了评估模型的数学能力,Google 的研究团队使用了多个源自竞赛的基准测试,包括 MATH、2024 年美国数学邀请赛(AIME)、数学奥德赛以及内部开发的评估 HiddenMath 和 IMO-Bench。
![]()
令人惊叹的是,数学专业版 Gemini 1.5 Pro 在这些测试中展现出超强的实力,在 MATH 基准测试中通过单一样本实现了 80.6% 的准确率,在抽取 256 个解决方案并选择一个候选答案 (rm@256) 时甚至达到了 91.1% 的准确率。这项性能与人类专家的表现相当,并且是在没有使用代码执行、定理证明库、谷歌搜索或其他工具的情况下实现的。
更重要的是,数学专业版 Gemini 1.5 Pro 不仅在 MATH 基准测试中表现出色,在其他数学测试中也展现出显著的改进。它能解决 AIME 中 4 倍多的问题,并在数学奥德赛、HiddenMath 和 IMO-Bench 中表现出显著的改进。
Gemini 1.5 Pro 的数学能力提升得益于其强大的长上下文理解能力、in-context learning 能力和更深层的推理能力。它能够理解复杂的数学问题,并通过多步骤推理和逻辑分析找到答案。
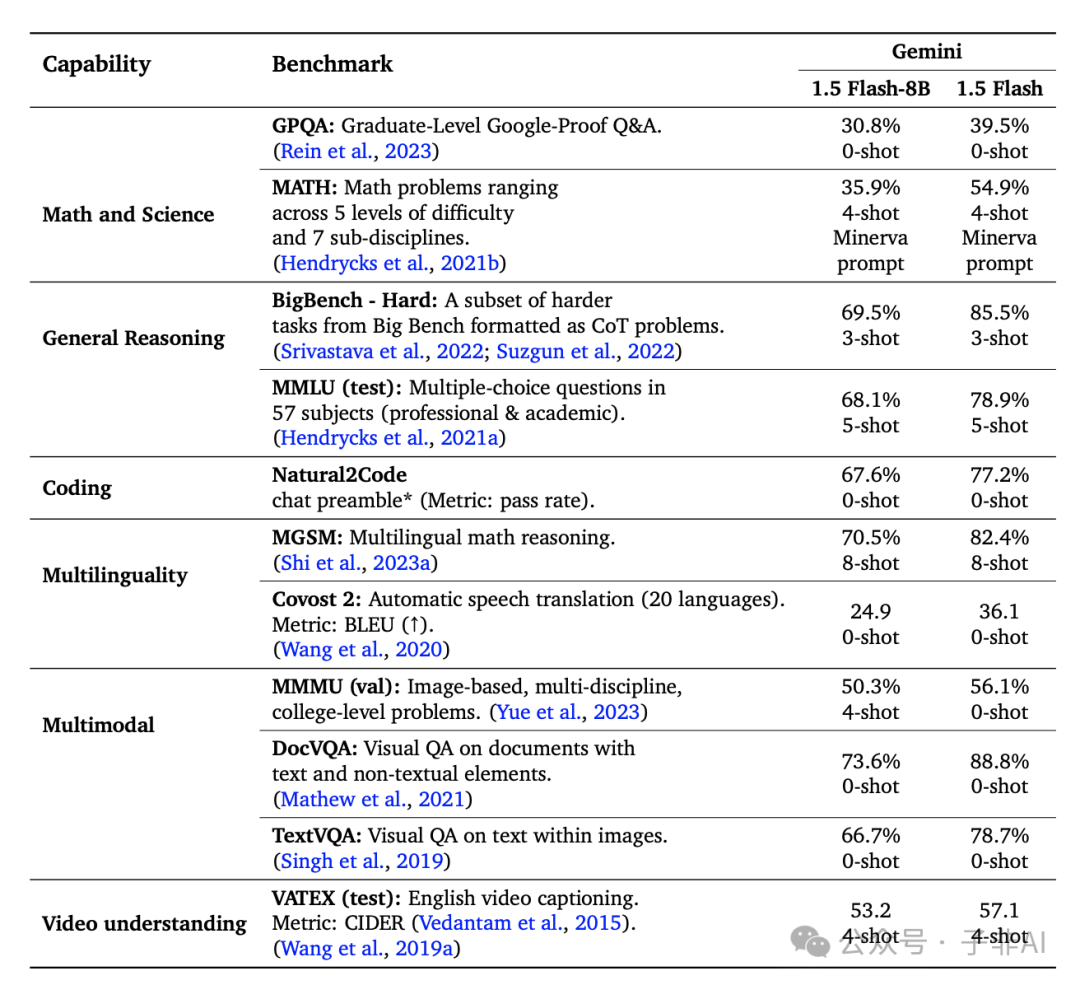
Flash-8B:速度与质量的完美平衡
除了强大的 Gemini 1.5 Pro,Google 还推出了 Flash-8B 模型,这是一款更小、更快、更高效的多模态模型,旨在实现速度与质量的完美平衡。
![]()
Flash-8B 继承了 Flash 的核心架构、优化和数据混合改进,并支持超过 100 万个标记的上下文窗口。它能够应用于大规模数据标注、高吞吐量代理服务等场景,为更广泛的用户提供高质量的 AI 服务。
安全性提升,构建负责任的 AI 未来
Google 深知,AI 技术的发展必须以安全和负责任为前提。因此,在开发 Gemini 1.5 Pro 的过程中,Google 高度重视模型的安全性,并针对提示注入攻击、记忆敏感数据和代表性危害等方面进行了专门的评估和改进。
结果表明,Gemini 1.5 Pro 和 Flash 在安全性方面取得了显著的进步,在多种安全评估中的违规率大幅降低,记忆敏感数据的风险也得到有效控制。
AI 评估新挑战,未来展望
Gemini 1.5 的出现,不仅标志着多模态 AI 迈入了百万级上下文理解的新纪元,也为 AI 评估带来了新的挑战。现有的基准测试大多针对短上下文模型设计,难以充分评估 Gemini 1.5 Pro 的真实能力。
未来,我们需要开发新的基准测试,来评估模型在长上下文中进行多层次推理和信息整合的能力。例如,可以要求模型整合分散在长文档中不同位置的多条信息,并进行推理或解决矛盾。
此外,我们还需要探索更高效的 AI 评估方法,例如利用自动化评估工具和人工评估相结合的方式,来降低评估成本并提高评估效率。
总而言之,Gemini 1.5 系列模型是 AI 发展史上的一次重大突破,它将多模态 AI 的能力提升到了一个全新的水平。随着技术的不断发展和完善,相信 Gemini 1.5 将在更多领域发挥其巨大潜力,为人类带来更多福祉。
附录:
模型卡片、详细的评估数据和示例、以及其他补充信息请参考原文附件。https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf

本文链接:https://google-gemini.cc/gemini_91.html
谷歌发布大模型gemini ai无焦虑谷歌母公司宣布削减gemini成本是多少谷歌gemini免费谷歌gemini免费使用谷歌发布大模型gemini网站谷歌的gemini是什么谷歌gemini视频解读谷歌gemini哪里可以用gemini谷歌ios谷歌gemini说明了什么