先做个广告:需要购买Gemini帐号或代充值Gemini会员,请加微信:gptchongzhi

哦,谷歌。你会在第一次尝试时就得到一个 AI 产品版本吗?
 推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
推荐使用Gemini中文版,国内可直接访问:https://ai.gpt86.top
在谷歌在一段光鲜亮丽的演示视频中向世界展示了其传闻已久的 ChatGPT 竞争对手 Gemini 后不到一个月——只是该公司因出现并最终被证实是演示者与 AI 之间的上演互动而面临批评——新的研究发现,现在消费者可以使用的最强大的 Gemini 版本, Gemini Pro 在大多数任务方面落后于 OpenAI 的 GPT-3.5 Turbo 大型语言模型 (LLM)。
是的,你没看错:谷歌全新的LLM,至少已经开发了几个月,在大多数任务上的表现都比OpenAI的旧、不那么前沿的免费模型差。毕竟,ChatGPT Plus 和 Enterprise 付费用户已经可以定期访问和使用底层的 GPT-4 和 GPT-4V(多模态产品)LLM,并且在今年的大部分时间里都可以访问前者。
这是根据卡内基梅隆大学(Carnegie Mellon University)的一组研究人员和一家名为BerriAI的企业的研究人员的工作得出的。
他们的论文“深入了解双子座的语言能力”昨天发表在同行评审和开放获取科学网站 arXiv.org 上。正如它在顶部附近明确指出的那样:“总而言之,我们发现,在所有任务中,截至撰写本文时(2023 年 12 月 19 日),Gemini 的 Pro 模型与当前版本的 OpenAI 的 GPT 3.5 Turbo 相比取得了相当但略逊一筹的准确性。
对于花了大量时间研究双子座及其领导层的谷歌研究人员来说,这个结论必须刺痛。我们已经联系了谷歌新闻发言人,了解该公司对这些调查结果的看法,并在收到回复后进行更新。
研究人员测试了什么
该论文继续指出,研究团队实际上测试了四种不同的LLM:Google Gemini Pro、OpenAI GPT-3.5 Turbo、GPT-4 Turbo和Mixtral 8x7B,这是来自资金雄厚的法国初创公司Mistral的新开源模型,上周以其突然、毫不客气的到来(作为种子链接删除,没有文档)及其高性能和基准分数(对AI性能的标准化评估)在AI社区掀起了一场风暴。
研究人员在 2023 年 12 月 11 日至 15 日的 4 天内使用了 AI 聚合网站 LiteLLM,并通过一组不同的提示运行了所有模型,包括向他们询问 57 个不同的多项选择题,“跨越 STEM、人文科学、社会科学”,作为“基于知识的 QA”测试的一部分。
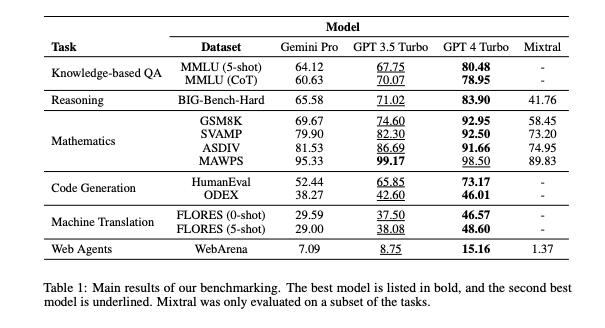
在那次测试中,“Gemini Pro 的准确度低于 GPT 3.5 Turbo,远低于 GPT 4 Turbo”,具体得分为 64.12/60.63(满分 100/100),而 GPT-3.5 Turbo 为 67.75/70.07,GPT-4 Turbo 为 80.48/78.95。请参阅其论文中包含的下表的第一行。
有趣的是,研究人员发现,当提示不同的LLM在标记为A、B、C或D的答案之间进行选择时,Gemini比其他模型不成比例地选择“D”的次数更多,无论它是否是正确的答案。
“双子座的标签分布非常偏斜,偏向于选择'D'的最终选择,这与GPT模型的结果形成鲜明对比,后者更加平衡,”该论文指出。“这可能表明Gemini在解决多项选择题方面没有进行过多的指导调整,这可能导致模型在答案排序方面存在偏见。
此外,研究人员观察到,Gemini 在几个特定类别的问题上比 GPT-3.5 Turbo 差,即人类性行为、形式逻辑、基础数学和专业医学。研究人员表示,这在很大程度上是由于Gemini拒绝回答一些问题,称由于其安全性和含量限制而无法遵守,研究人员认为这是他们分级/基准测试中的错误回应。
Gemini Pro 确实在两类多项选择题中优于 GPT-3.5 Turbo——安全和高中微观经济学,并且进一步打击了谷歌的雄心壮志,并表示,“对于 Gemini Pro 优于 GPT 3.5 Turbo 的两项任务,收益微乎其微。此外,GPT-4 仍然在所有测试的模型中占据主导地位。
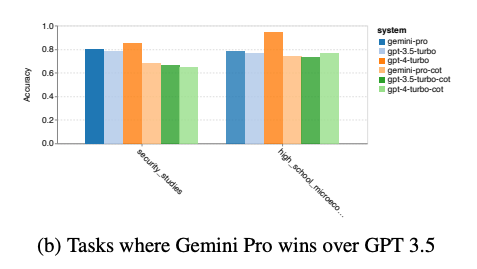
为了公平起见,研究人员小心翼翼地注意到,在另一种情况下,它的表现优于 GPT-3.5:当 LLM 的输出长度大于 900 个标记时(标记是指分配给不同单词、字母组合和符号的不同数值,这反映了模型内部对不同概念的组织)。
研究人员在另一类问题“通用推理”上测试了这些模型,其中没有给出答案选项。取而代之的是,LLM被要求阅读一个逻辑问题,并用他们认为正确的答案来回答它。
研究人员再次发现,“Gemini Pro 的精度略低于 GPT 3.5 Turbo,远低于 GPT 4 Turbo......Gemini Pro 在更长、更复杂的问题上表现不佳,而 GPT 模型对此更稳健。GPT 4 Turbo 尤其如此,即使在较长的问题上也几乎没有退化,这表明它能够理解更长、更复杂的查询,令人印象深刻。
然而,Gemini 确实设法在两个子类别上击败了“所有 GPT 模型”,包括 GPT-4:单词排序和符号操作(戴克语言任务)。正如研究人员所说:“双子座特别擅长单词重新排列和以正确的顺序产生符号。
在数学和数学推理方面,研究人员发现了与测试其他主题类似的结果:“Gemini Pro 的准确率略低于 GPT 3.5 Turbo,远低于 GPT 4 Turbo。
认为双子座可能会在编程中救赎自己吗?再想一想。当给定两个不同的不完整 Python 代码字符串来完成时,Gemini 的表现“低于 GPT 3.5 Turbo,在两项任务上都远低于 GPT 4 Turbo”。
当被要求充当“网络代理”,根据提示的指示代表用户浏览公共互联网并完成任务时,“Gemini-Pro 的性能相当,但略差于 GPT-3.5-Turbo。
Gemini 确实在一个领域胜过所有其他模型,这个领域似乎特别适合谷歌之前的技能组合:在语言之间翻译内容。正如研究人员所指出的那样:“Gemini Pro 在 20 种语言中的 8 种语言上优于 GPT 3.5 Turbo 和 GPT 4 Turbo,并在 4 种语言上取得了最佳表现。但即使是这个结果也被“Gemini Pro表现出阻止大约10种语言对的强烈趋势”这一事实所玷污,这表明存在过分热心的内容审核/安全系统。
这对谷歌的人工智能野心和用户意味着什么?
这些结果显然打击了谷歌在生成式人工智能竞赛中与OpenAI正面交锋的雄心壮志,而且由于更强大的谷歌Gemini Ultra模型要到明年才能推出,这可能意味着谷歌至少在那之前在人工智能性能方面仍然落后。
不过,有趣的是,该研究还表明,Mistral 的新 LLM Mixtral 8x7B——它采用“专家混合”方法,其中几个不同的小型 AI 模型链接在一起,每个模型处理它们理想地专门针对的不同任务集——在大多数情况下,性能也比 OpenAI 的 GPT-3.5 Turbo 差得多。据研究人员称,Gemini Pro“在我们检查的每项任务上都优于Mixtral”。
这暗示了谷歌人工智能工作的一个亮点:它仍然比尖端的开源更好。
然而,总的来说,很难不从这项研究中走出来,给人的印象是,OpenAI目前仍然是面向消费者和企业的生成式人工智能之王。
宾夕法尼亚大学沃顿商学院教授伊桑·莫利克(Ethan Mollick)等人工智能影响者似乎在很大程度上同意这一点。正如 Mollick 今天在 X 上发布的那样:“对于大多数个别情况,您希望使用最好的 AI,这显然仍然是 GPT-4......至少在新的一年里Gemini Ultra发布之前。
这篇论文证实,谷歌的新 Gemini Pro 相当于 OpenAI 的免费 ChatGPT 3.5.5.对于大多数个别情况,你想使用最好的 AI,这显然仍然是 GPT-4,可通过 ChatGPT Plus 或 Bing 访问。(至少在新的一年Gemini Ultra发布之前) https://t.co/eYo3dCHphb